
AskSia

Question
Computer Science
Posted about 2 years ago
In a 2019 research paper, a group of researchers analyzed two machine
learning algorithms for automated hate speech detection. Both algorithms
were trained on thousands of tweets that had been annotated by
crowdsourced workers as being offensive or not.
To test the algorithms, the researchers collected millions of tweets that
were classified as written in either the dialect of African American English
(AAE) dialect or White-aligned English. How?
The researchers ran the algorithms over each tweet and recorded the rate
at which non-offensive tweets were marked as offensive as well as the rate
at which offensive tweets were marked as non-offensive.
Algorithm 1
AAE
White-aligned
9.0%
46.3%
Labeled offensive, but wasn't actually
1.1%
7.9%
Labeled not offensive, but actually was
Algorithm 2
AAE
White-aligned
4.5%
26%
Labeled offensive, but wasn't actually
30.5%
4.2%
Labeled not offensive, but actually was
Which of the following statements is supported by that data?
Choose 1 answer:
Algorithm 1 contain bias that results in more often falsely labeling
A
AAE tweets as "not offensive" versus White tweets, while
Algorithm 2 has the opposite bias.
Algorithm 1 contain bias that results in more often falsely labeling
B
White tweets as "offensive" versus AAE tweets, while Algorithm 2
has the opposite bias.
Algorithm 1 contain bias that results in more often falsely labeling
C
White tweets as "not offensive" versus AAE tweets, while
Algorithm 2 has the opposite bias.
Both algorithms contain bias that results in more often falsely
D
labeling AAE tweets as "offensive" versus White tweets.
Both algorithms contain bias that results in more often falsely
E
labeling White tweets as "offensive" versus AAE tweets.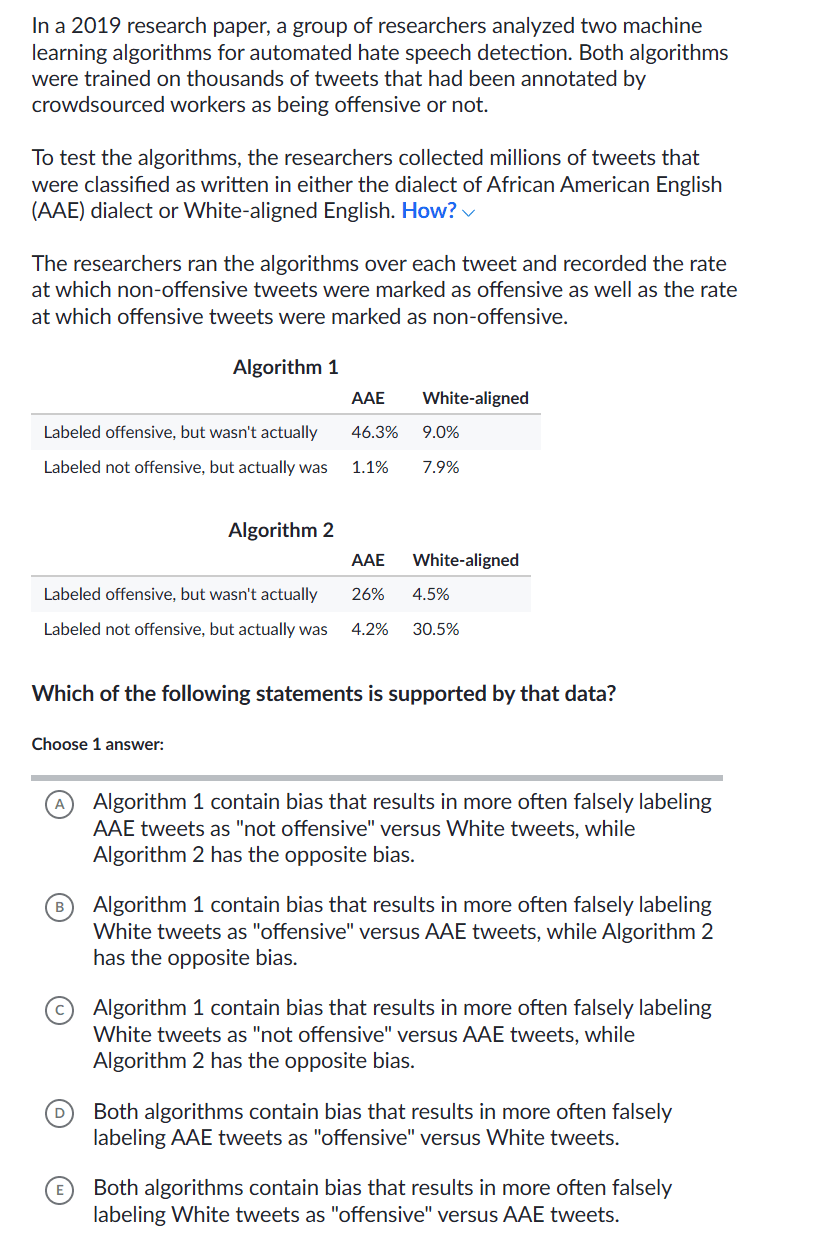
 Sign in to unlock the answer
Sign in to unlock the answer
Answer from Sia
Posted about 2 years ago
B
Key Concept
Bias in Hate Speech Detection Algorithms
Explanation
Algorithm 1 shows a higher false positive rate for White-aligned tweets (9.0%) compared to AAE tweets (46.3%), indicating a bias towards falsely labeling White tweets as offensive. Conversely, Algorithm 2 shows a higher false positive rate for AAE tweets (26%) compared to White-aligned tweets (4.5%), indicating a bias towards falsely labeling AAE tweets as offensive.
Not the question you are looking for? Ask here!
Enter question by text
Enter question by image

Unlock Smarter Learning with AskSia Super!
Join Super, our all-in-one AI solution that can greatly improve your learning efficiency.
30% higher accuracy than GPT-4o
Entire learning journey support
The most student-friendly features

Study Other Question